HashMap 是难点也是重点,更是面试中的常客,充分了解 HashMap 绝对有助于提升编程的内功心法。本文重点是对 JDK1.7 和 JDK1.8 中其实现方式的变化进行分析学习。
引
不同集合底层数据结构?
| 集合实现 | Object数组 | |
|---|---|---|
| List | ArrayList | Object数组 |
| Vector | Object数组 | |
| LinkedList | 双向链表(JDK1.6及之前为循环链表) | |
| Set | HashSet(无序、唯一) | 基于 HashMap 实现 |
| LinkedHashSet | 继承自 HashSet ,内部通过 LinkedHashMap 实现。 | |
| TreeSet(有序、唯一) | 红黑树(自平衡BST) | |
| Map | HashMap | JDK1.8 之前数组+链表,JDK1.8开始数组+链表+红黑树 |
| LinkedHashMap | 继承自 HashMap 并在其基础上增加了一条双向链表,使得其可以保持键值对插入的顺序,实现了访问顺序相关逻辑。 | |
| HashTable | 数组+链表 | |
| TreeMap | 红黑树,基于 Key 进行排序 |
说HashTable、HashMap ?
- HashMap 是非线程安全的,而 HashTable 是线程安全的,HashTable 内的方法大多都经过
synchronized修饰;因为线程安全的问题上的处理,导致 HashMap 效率要略高于 HashTable ;并且 HashTable 已经是基本被淘汰的方案了! - HashMap 中允许存在一个为 null 的 key (value 可以有多个 null),但是如果向 HashTable 中 put 一个为 null 的 key,会直接抛出 NullPointerException 。
- HashTable 的默认初始容量大小是 11,HashMap 的默认初始容量大小是 16;如果创建时指定初始容量,HashTable 会直接使用指定的容量,HashMap 会将指定容量扩充为一个 2 的幂大小。(具体原因,在正文会进行分析)
- JDK1.8 之后 HashMap 当链表长度大于阈值(默认 8 )时,先检查当前数组数组的长度,数组长度小于 64 则先进行数组扩容,否则转换为红黑树,以减少 Hash 冲突从而减少搜索时间。HashTable 没有这个机制。
HashSet用过么?
HashSet 的底层就是一个 HashMap ,HashSet 源码很少,大多直接调用调用了 HashMap 的实现。
和 HashMap 的区别:HashMap 实现了 Map 接口,存储键值对,其 hashcode 使用 Key进行计算;HashSet 实现了Set 接口,直接存储数据对象,使用成员对象计算 hashcode值。
HashSet 如何保证插入对象唯一:当元素插入时,先调用hash()方法计算插入对象的 hashcode值去得到对象加入的位置,同时会和集合中其他的对象的 hashcode 值进行比较,如果没有相同的 hashcode 值则说明对象没重复;如果 hashcode 值重复,这是会调用对象的equals()方法来检查 hashcode 相同的对象是否真的相同,最终相同则插入失败,否则成功。
PS
- 通常
==是判断两个变量或实例指向的内存空间是否相同,即引用是否相同 ;通常equals()是判断两个变量或实例指向的内存空间的值是否相同,即值是否相同 。 - 如果两个对象相等,hashcode 一定相同;hashcode相同,对象不一定相等。
hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
正文
历史课 (* ̄︶ ̄) JDK1.8 前后的变化
JDK1.8 之前 HashMap 底层是采用数组+链表的实现。HashMap 通过 Key 的 hashcode 经过hash()处理后得到 hash 值:
1 | static int hash(int h) { |
在通过(n-1)&hash判断当前元素存放的位置(n数组长度),最后如果计算得到的位置上存在元素,就判断这个元素和待插入元素的 hash 和 Key 是否相同,如果相同则进行覆盖,否则链表散列解决冲突。
JDK1.8 之后 HashMap 底层采用数组+链表+红黑树的实现。hash 的计算方法相较于之前更简洁,但是原理不变:
1 | static final int hash(Object key) { |
依然是采用之前那套方法找到待插入元素的位置,区别在于当发生 hash 冲突之后,如果这个位置上的链表大于阈值(默认是 8 ),检查当前数组的长度,如果长度小于 64 则进行数组扩容,否则将链表转化为红黑树,从而增加之后的搜索效率。
HashMap数组长度为什么是2的幂次方?
插个题外话 HashMap 是如何保证总是使用2的幂作为数组大小的?看指定初始容量的构造方法:
1 | static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认大小16 |
最终调用了tableSizeFor(initialCapacity)方法,这个方法保证了总是使用2的幂作为数组大小:
1 | /** |
回归正题,为什么采用2的幂大小?hash 取值范围是[-2^8,2^8-1],当然不能真的创建一个 42亿大小的数组,所以 hash 值用之前要对数组长度取模,得到的余数才是真正的存放位置,这点和前面”历史课”散列计算的方法(n - 1) & hash是匹配的!
(n - 1) & hash采用位运算的方式取余,相较于使用 % 操作的运算效率要高。如果数组的长度是 2的幂 则可以使(n - 1) & hash和hash % n这两个运算的结果相同!
线程安全问题!
主要原因是因为并发场景下的 rehash 会造成元素之间形成一个循环链表。
所谓 rehash : 当增大 Hash表 的容量,整个 Hash表 里所有无素的插入位置都需要被重算一遍。这叫rehash,这个成本相当的大。 关于rehash—— https://coolshell.cn/articles/9606.html
不过 JDK1.8 后解决了这个问题,但是在多线程的情况下使用 HashMap 还是会存在数据丢失等问题,并发场景下推荐使用 ConcurrentHashMap。
ConcurrentHashMap
说到 HashMap 的线程安全问题,就不得不提到 J.U.C 包下的 ConcurrentHashMap ,这也是面试的常客。
先介绍一下 ConcurrentHashMap :
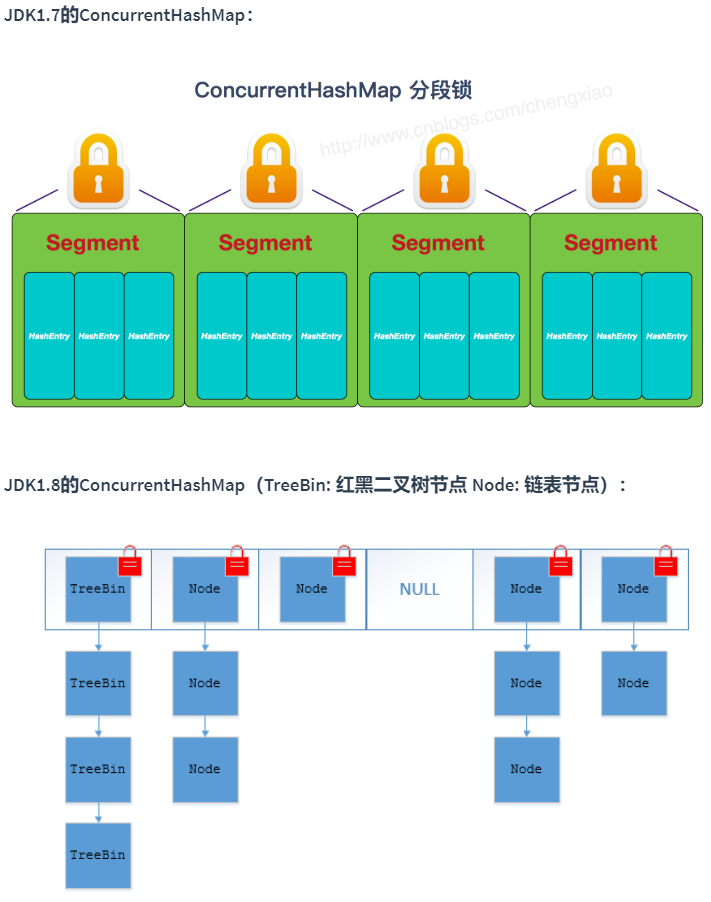
- 数据结构:JDK1.7的 ConcurrentHashMap 底层采用分段数组+链表实现,JDK1.8 开始其数据结构采用和 HashMap 一样的数组+链表+红黑树,数组是本体,链表和红黑树主要是为了解决哈希冲突存在的。
- 如何实现线程安全:在 JDK1.7 的时候,ConcurrentHashMap 采用分段锁对整个桶数组进行了分割分段(Segment),每一把锁只锁住容器中一部分的数据,多线程访问容器里不同数据段的数据,就不会引发锁的竞争,提高了并发量。从 JDK1.8 开始不再使用之前的Segment的概念,改为直接使用Node数组+链表+红黑树,并发控制使用
synchronize和CAS来实现。整个看起来像是优化过且线程安全的 HashMap,虽然 JDK1.8 的源码中还能看到 Segment 的数据结构,但是已经被简化了属性,只是为了兼容旧版本。
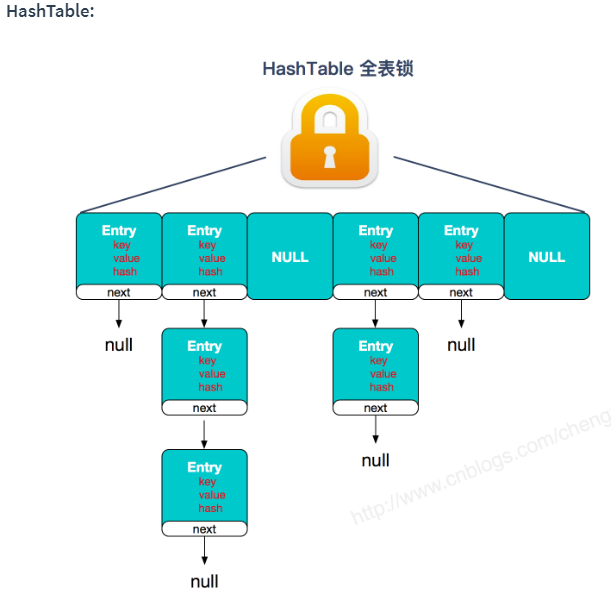
PS:这里提一下 HashTable 也是用 synchronize进行并发控制,但是效率缺很低的原因。因为其所有方法synchronize时使用的是同一把锁,所以当一个线程正在访问同步方法时,其他的线程如果也想去访问同步方法时,一定会进入阻塞或轮询状态形成一种串行化的操作,并且竞争可能会越来越激烈,从而导致效率大打折扣。
这里看一下 HashTable 和 ConcurrentHashMap 锁的对比:
再说 ConcurrentHashMap 线程安全
JDK1.7 首先将数据分成一段一段的进行存储,每一段数据有一把锁,当一个线程访问某段数据时,就去获得这段数据对应的锁,并不对其他段的数据造成影响,即其他线程可以对其他段数据进行访问而不被阻塞。
此时的 ConcurrentHashMap 是由 Segment 数据结构和 HashEntry 数组结构组成。
Segment 继承自 ReentrantLock,所以是一种可重入锁,其作用就是扮演锁的角色。HashEntry 才是用于存储键值对数据的。
1 | static class Segment<K,V> extends ReentrantLock implements Serializable {} |
一个 ConcurrentHashMap 里包含一个 Segment 数组,Segment 的结构和 此时的HashMap 类似,是一种数组+链表的结构,一个 Segment 对应包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 可以锁住其对应的一个 HashEntry 数组中的元素,即当对一个 HashEntry 数组中的元素进行修改时,必须先获得其对应的 Segment 锁。
JDK1.8 的 ConcurrentHashMap 取消了 Segment 分段锁的思想,改为CAS和synchronize来保证并发安全。数据结构和此时的 HashMap 的结构类似数组+链表+红黑树。前文说过的 Java 8 在链表长度上超过阈值(8)并且数组长度超过 64 时将链表转换为红黑树。
synchronize只会锁住当前链表或红黑树的首节点,只要 hash 不冲突,就不会发生并发,效率大大提升。
补充
Comparable 和 Comparator
Comparable 接口出自 java.lang 包下,接口下只有一个
compareTo(T o)抽象方法,如果希望 TreeMap/TreeSet 插入元素时希望采用自定义排序,或者希望自定义 Set 去重规则,可以让插入对象实现这个接口重写方法:1
public int compareTo(T o);
Comparator 是个函数式接口出自 java.util 包下,这个接口下方法有二十多个方法,其中有一个抽象方法
compare(T o1, T o2),其常用方式是调用带参数的Collections.sort()时传一个 Comparator 的匿名类,支持采用 Lambda 的方式实现:1
int compare(T o1, T o2);
当我们需要对一个集合进行自定义排序或者自定义 Set 去重规则时,可以重写 compare(T o1, T o2)或者 compareTo(T o);
例如:当我们需要对某一个集合实现两种自定义排序的时候,比如对 Student 对象元素中的姓名采用一种自定义排序方式、学校名采用另一种自定义排序方式的需求,可以重写 compareTo(T o)方法实现一种、再实现 Comparable 接口实现另一种方法,也可以用两个 Comparator 分别重写compareTo(T o)方法进行实现,第二个方案可以使用两个带参数的 Collections.sort()实现。
本人菜鸟,有错误请告知,感激不尽!
更多题解和源码:github